Netty 是什么
Netty: http://netty.io/
Netty is an asynchronous event-driven network application framework for rapid development of maintainable high performance protocol servers & clients.
官方的解释最精准了,期中最吸引人的就是高性能了。但是很多人会有这样的疑问:直接用 NIO 实现的话,一定会更快吧?就像我直接手写 JDBC 虽然代码量大了点,但是一定比 iBatis 快!
但是,如果了解 Netty 后你才会发现,这个还真不一定!
利用 Netty 而不用 NIO 直接写的优势有这些:
- 高性能高扩展的架构设计,大部分情况下你只需要关注业务而不需要关注架构
Zero-Copy 技术尽量减少内存拷贝- 为 Linux 实现 Native 版 Socket
- 写同一份代码,兼容 java 1.7 的 NIO2 和 1.7 之前版本的 NIO
Pooled Buffers 大大减轻声请 Buffer 和释放 Buffer 的压力- ……
特性太多,大家可以去看一下《Netty in Action》这本书了解更多。
另外,Netty 源码是一本很好的教科书!大家在使用的过程中可以多看看它的源码,非常棒!
瓶颈是什么
想要做一个长链服务的话,最终的目标是什么?而它的瓶颈又是什么?
其实目标主要就两个:
- 更多的连接
- 更高的 QPS
所以,下面就针对这连个目标来说说他们的难点和注意点吧。
更多的连接
非阻塞 IO
其实无论是用 Java NIO 还是用 Netty,达到百万连接都没有任何难度。因为它们都是非阻塞的 IO,不需要为每个连接创建一个线程了。
欲知详情,可以搜索一下BIO,NIO,AIO的相关知识点。
Java NIO 实现百万连接
ServerSocketChannel ssc = ServerSocketChannel.open();
Selector sel = Selector.open();
ssc.configureBlocking(false);
ssc.socket().bind(new InetSocketAddress(8080));
SelectionKey key = ssc.register(sel, SelectionKey.OP_ACCEPT);
while(true) {
sel.select();
Iterator it = sel.selectedKeys().iterator();
while(it.hasNext()) {
SelectionKey skey = (SelectionKey)it.next();
it.remove();
if(skey.isAcceptable()) {
ch = ssc.accept();
}
}
}
这段代码只会接受连过来的连接,不做任何操作,仅仅用来测试待机连接数极限。
大家可以看到这段代码是 NIO 的基本写法,没什么特别的。
Netty 实现百万连接
NioEventLoopGroup bossGroup = new NioEventLoopGroup();
NioEventLoopGroup workerGroup= new NioEventLoopGroup();
ServerBootstrap bootstrap = new ServerBootstrap();
bootstrap.group(bossGroup, workerGroup);
bootstrap.channel( NioServerSocketChannel.class);
bootstrap.childHandler(new ChannelInitializer<SocketChannel>() {
@Override protected void initChannel(SocketChannel ch) throws Exception {
ChannelPipeline pipeline = ch.pipeline();
}});
bootstrap.bind(8080).sync();
这段其实也是非常简单的 Netty 初始化代码。同样,为了实现百万连接根本没有什么特殊的地方。
瓶颈到底在哪
上面两种不同的实现都非常简单,没有任何难度,那有人肯定会问了:实现百万连接的瓶颈到底是什么?
其实只要 Java 中用的是非阻塞 IO(NIO 和 AIO 都算),那么它们都可以用单线程来实现大量的 Socket 连接。 不会像 BIO 那样为每个连接创建一个线程,因为代码层面不会成为瓶颈。
其实真正的瓶颈是在 Linux 内核配置上,默认的配置会限制全局最大打开文件数(Max Open Files)还会限制进程数。 所以需要对 linux 内核配置进行一定的修改才可以。
这个东西现在看似很简单,按照网上的配置改一下就行了,但是大家一定不知道第一个研究这个人有多难。
这里直接贴几篇文章,介绍了相关配置的修改方式:
构建C1000K的服务器
淘宝技术分享 HTTP长连接200万尝试及调优
如何验证
让服务器支持百万连接一点也不难,我们当时很快就搞定了一个测试服务端,但是最大的问题是,我怎么去验证这个服务器可以支撑百万连接呢?
我们用 Netty 写了一个测试客户端,它同样用了非阻塞 IO ,所以不用开大量的线程。 但是一台机器上的端口数是有限制的,用root权限的话,最多也就 6W 多个连接了。 所以我们这里用 Netty 写一个客户端,用尽单机所有的连接吧。
NioEventLoopGroup workerGroup = new NioEventLoopGroup();
Bootstrap b = new Bootstrap();
b.group(workerGroup);
b.channel( NioSocketChannel.class);
b.handler(new ChannelInitializer<SocketChannel>() {
@Override
public void initChannel(SocketChannel ch) throws Exception {
ChannelPipeline pipeline = ch.pipeline();
}
});
for (int k = 0; k < 60000; k++) {
b.connect(127.0.0.1, 8080);
}
代码同样很简单,只要连上就行了,不需要做任何其他的操作。
这样只要找到一台电脑启动这个程序即可。这里需要注意一点,客户端最好和服务端一样,修改一下 Linux 内核参数配置。
怎么去找那么多机器
按照上面的做法,单机最多可以有 6W 的连接,百万连接起码需要17台机器!
如何才能突破这个限制呢?其实这个限制来自于网卡。 我们后来通过使用虚拟机,并且把虚拟机的虚拟网卡配置成了桥接模式解决了问题。
根据物理机内存大小,单个物理机起码可以跑4-5个虚拟机,所以最终百万连接只要4台物理机就够了。
讨巧的做法
除了用虚拟机充分压榨机器资源外,还有一个非常讨巧的做法,这个做法也是我在验证过程中偶然发现的。
根据 TCP/IP 协议,任何一方发送FIN后就会启动正常的断开流程。而如果遇到网络瞬断的情况,连接并不会自动断开。
那我们是不是可以这样做?
- 启动服务端,千万别设置 Socket 的
keep-alive属性,默认是不设置的
- 用虚拟机连接服务器
- 强制关闭虚拟机
- 修改虚拟机网卡的 MAC 地址,重新启动并连接服务器
- 服务端接受新的连接,并保持之前的连接不断
我们要验证的是服务端的极限,所以只要一直让服务端认为有那么多连接就行了,不是吗?
经过我们的试验后,这种方法和用真实的机器连接服务端的表现是一样的,因为服务端只是认为对方网络不好罢了,不会将你断开。
另外,禁用keep-alive是因为如果不禁用,Socket 连接会自动探测连接是否可用,如果不可用会强制断开。
更高的 QPS
由于 NIO 和 Netty 都是非阻塞 IO,所以无论有多少连接,都只需要少量的线程即可。而且 QPS 不会因为连接数的增长而降低(在内存足够的前提下)。
而且 Netty 本身设计得足够好了,Netty 不是高 QPS 的瓶颈。那高 QPS 的瓶颈是什么?
是数据结构的设计!
如何优化数据结构
首先要熟悉各种数据结构的特点是必需的,但是在复杂的项目中,不是用了一个集合就可以搞定的,有时候往往是各种集合的组合使用。
既要做到高性能,还要做到一致性,还不能有死锁,这里难度真的不小…
我在这里总结的经验是,不要过早优化。优先考虑一致性,保证数据的准确,然后再去想办法优化性能。
因为一致性比性能重要得多,而且很多性能问题在量小和量大的时候,瓶颈完全会在不同的地方。 所以,我觉得最佳的做法是,编写过程中以一致性为主,性能为辅;代码完成后再去找那个 TOP1,然后去解决它!
解决 CPU 瓶颈
在做这个优化前,先在测试环境中去狠狠地压你的服务器,量小量大,天壤之别。
有了压力测试后,就需要用工具来发现性能瓶颈了!
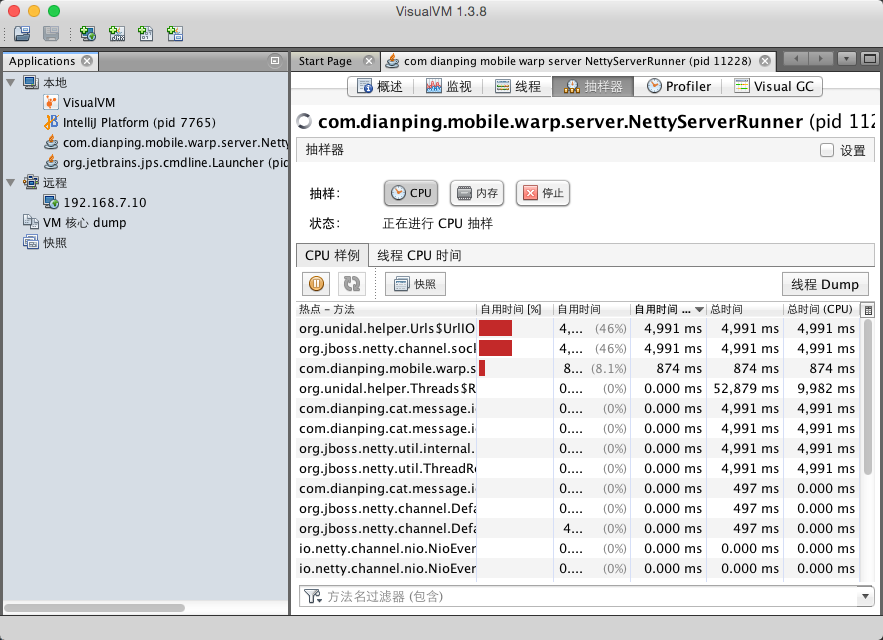
我喜欢用的是 VisualVM,打开工具后看抽样器(Sample),根据自用时间(Self Time (CPU))倒序,排名第一的就是你需要去优化的点了!
备注:Sample 和 Profiler 有什么区别?前者是抽样,数据不是最准但是不影响性能;后者是统计准确,但是非常影响性能。 如果你的程序非常耗 CPU,那么尽量用 Sample,否则开启 Profiler 后降低性能,反而会影响准确性。
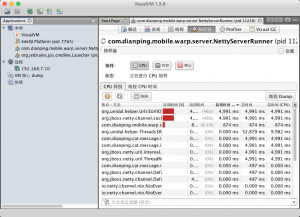
还记得我们项目第一次发现的瓶颈竟然是ConcurrentLinkedQueue这个类中的size()方法。 量小的时候没有影响,但是Queue很大的时候,它每次都是从头统计总数的,而这个size()方法我们又是非常频繁地调用的,所以对性能产生了影响。
size()的实现如下:
public int size() {
int count = 0;
for (Node<E> p = first(); p != null; p = succ(p))
if (p.item != null)
if (++count == Integer.MAX_VALUE)
break;
return count;
}
后来我们通过额外使用一个AtomicInteger来计数,解决了问题。但是分离后岂不是做不到高一致性呢? 没关系,我们的这部分代码关心最终一致性,所以只要保证最终一致就可以了。
总之,具体案例要具体分析,不同的业务要用不同的实现。
解决 GC 瓶颈
GC 瓶颈也是 CPU 瓶颈的一部分,因为不合理的 GC 会大大影响 CPU 性能。
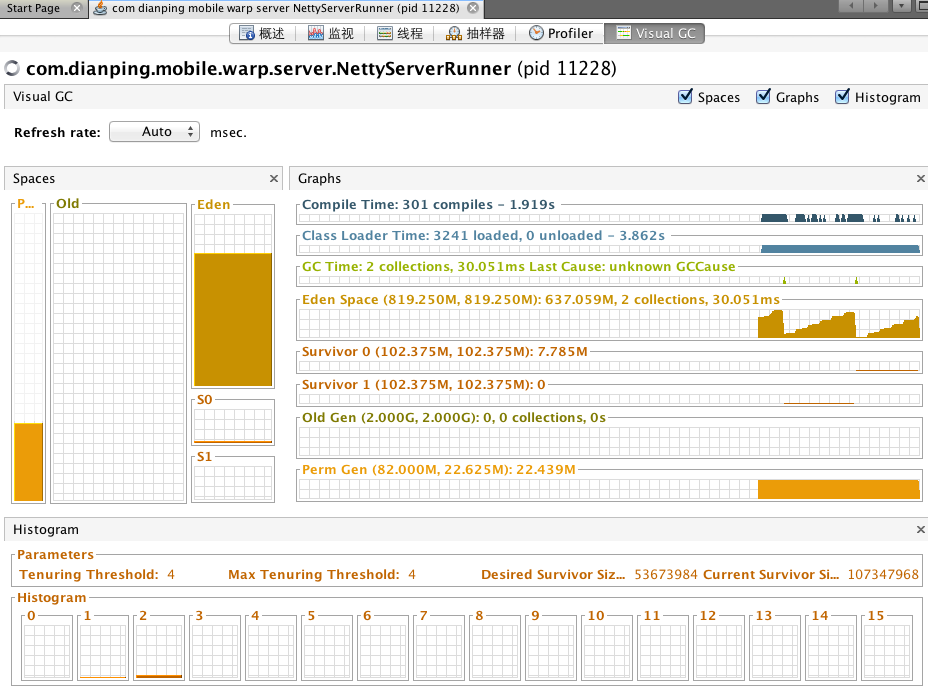
这里还是在用 VisualVM,但是你需要装一个插件:VisualGC
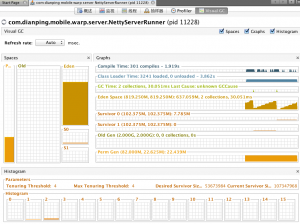
有了这个插件后,你就可以直观的看到 GC 活动情况了。
按照我们的理解,在压测的时候,有大量的 New GC 是很正常的,因为有大量的对象在创建和销毁。
但是一开始有很多 Old GC 就有点说不过去了!
后来发现,在我们压测环境中,因为 Netty 的 QPS 和连接数关联不大,所以我们只连接了少量的连接。内存分配得也不是很多。
而 JVM 中,默认的新生代和老生代的比例是1:2,所以大量的老生代被浪费了,新生代不够用。
通过调整 -XX:NewRatio 后,Old GC 有了显著的降低。
但是,生产环境又不一样了,生产环境不会有那么大的 QPS,但是连接会很多,连接相关的对象存活时间非常长,所以生产环境更应该分配更多的老生代。
总之,GC 优化和 CPU 优化一样,也需要不断调整,不断优化,不是一蹴而就的。
其他优化
如果你已经完成了自己的程序,那么一定要看看《Netty in Action》作者的这个网站:Netty Best Practices a.k.a Faster == Better。
相信你会受益匪浅,经过里面提到的一些小小的优化后,我们的整体 QPS 提升了很多。
最后一点就是,java 1.7 比 java 1.6 性能高很多!因为 Netty 的编写风格是事件机制的,看似是 AIO。 可 java 1.6 是没有 AIO 的,java 1.7 是支持 AIO 的,所以如果用 java 1.7 的话,性能也会有显著提升。
最后成果
经过几周的不断压测和不断优化了,我们在一台16核、120G内存(JVM只分配8G)的机器上,用 java 1.6 达到了60万的连接和20万的QPS。
其实这还不是极限,JVM 只分配了8G内存,内存配置再大一点连接数还可以上去;
QPS 看似很高,System Load Average 很低,也就是说明瓶颈不在 CPU 也不在内存,那么应该是在 IO 了! 上面的 Linux 配置是为了达到百万连接而配置的,并没有针对我们自己的业务场景去做优化。
因为目前性能完全够用,线上单机 QPS 最多才 1W,所以我们先把精力放在了其他地方。 相信后面我们还会去继续优化这块的性能,期待 QPS 能有更大的突破!