29.2 BSD Packet Filter (BPF)
4.4BSD and many other Berkeley-derived
implementations support BPF, the BSD packet filter. The
implementation of BPF is described in Chapter 31 of TCPv2. The
history of BPF, a description of the BPF pseudomachine, and a
comparison with the SunOS 4.1.x NIT packet filter is provided in
[McCanne and Jacobson 1993].
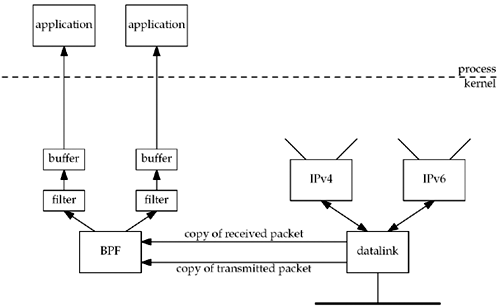
Each datalink driver calls BPF right before a
packet is transmitted and right after a packet is received, as
shown in Figure 29.1.
Examples of these calls for an Ethernet
interface are in Figures 4.11 and 4.19 of TCPv2. The reason for
calling BPF as soon as possible after reception and as late as
possible before transmission is to provide accurate timestamps.
While it is not hard to provide a tap into the
datalink to catch all packets, the power of BPF is in its filtering
capability. Each application that opens a BPF device can load its
own filter, which is then applied by BPF to each packet. While some
filters are simple (the filter " udp or tcp" receives only
UDP or TCP packets), others can examine fields in the packet
headers for certain values. For example,
tcp and port 80 and tcp[13:1] & 0x7 != 0
was used in Chapter 14 of TCPv3 to collect only
TCP segments to or from port 80 that had either the SYN, FIN, or
RST flags on. The expression tcp[13:1] refers to the
1-byte value starting at byte offset 13 from the start of the TCP
header.
BPF implements a register-based filter machine
that applies application-specific filters to each received packet.
While one can write filter programs in the machine language of this
pseudomachine (which is described on the BPF man page), the
simplest interface is to compile ASCII strings (such as the one
beginning with tcp that we just showed) into this machine
language using the pcap_compile function that we will
describe in Section 29.7.
Three techniques are used by BPF to reduce its
overhead:
-
The BPF filtering is within the kernel, which
minimizes the amount of data copied from BPF to the application.
This copy, from kernel space to user space, is expensive. If every
packet was copied, BPF could have trouble keeping up with fast
datalinks.
-
Only a portion of each packet is passed by BPF
to the application. This is called the snapshot length, or snaplen. Most applications need only the
packet headers, not the packet data. This also reduces the amount
of data copied by BPF to the application. tcpdump, for
example, defaults this value to 96, which allows room for a 14-byte
Ethernet header, a 40-byte IPv6 header, a 20-byte TCP header, and
22 bytes of data. But, to print additional information for other
protocols (e.g., DNS and NFS) requires the user to increase this
value when tcpdump is run.
-
BPF buffers the data destined for an application
and this buffer is copied to the application only when the buffer
is full, or when the read timeout
expires. This timeout value can be specified by the application.
tcpdump, for example, sets the timeout to 1000 ms, while
the RARP daemon sets it to 0 (since there are few RARP packets, and
the RARP server needs to send a response as soon as it receives the
request). The purpose of the buffering is to reduce the number of
system calls. The same number of packets are still copied between
BPF and the application, but each system call has an overhead, and
reducing the number of system calls always reduces the overhead.
(Figure 3.1 of APUE compares the overhead of the read
system call, for example, when reading a given file in different
chunk sizes varying between 1 byte and 131,072 bytes.)
Although we show only a single buffer in
Figure 29.1, BPF maintains
two buffers for each application and fills one while the other is
being copied to the application. This is the standard double-buffering technique.
In Figure
29.1, we show only the BPF reception of packets: packets
received by the datalink from below (the network) and packets
received by the datalink from above (IP). The application can also
write to BPF, causing packets to be sent out the datalink, but most
applications only read from BPF. There is no reason to write to BPF
to send IP datagrams because the IP_HDRINCL socket option
allows us to write any type of IP datagram desired, including the
IP header. (We show an example of this in Section 29.7.) The
only reason to write to BPF is to send our own network packets that
are not IP datagrams. The RARP daemon does this, for example, to
send its RARP replies, which are not IP datagrams.
To access BPF, we must open a BPF
device that is not currently open. For example, we could try
/dev/bpf0, and if the error return is EBUSY, then
we could try /dev/bpf1, and so on. Once a device is
opened, about a dozen ioctl commands set the
characteristics of the device: load the filter, set the read
timeout, set the buffer size, attach a datalink to the BPF device,
enable promiscuous mode, and so on. I/O is then performed using
read and write.

|