首先B站是个学习的好地方
1 先准备数据
源数据用歌曲比较好,因为歌曲里人声的高中低音都有,学习的效果比较好
先一张专集就可以
2 使用Ultimate Vocal Remover处理数据
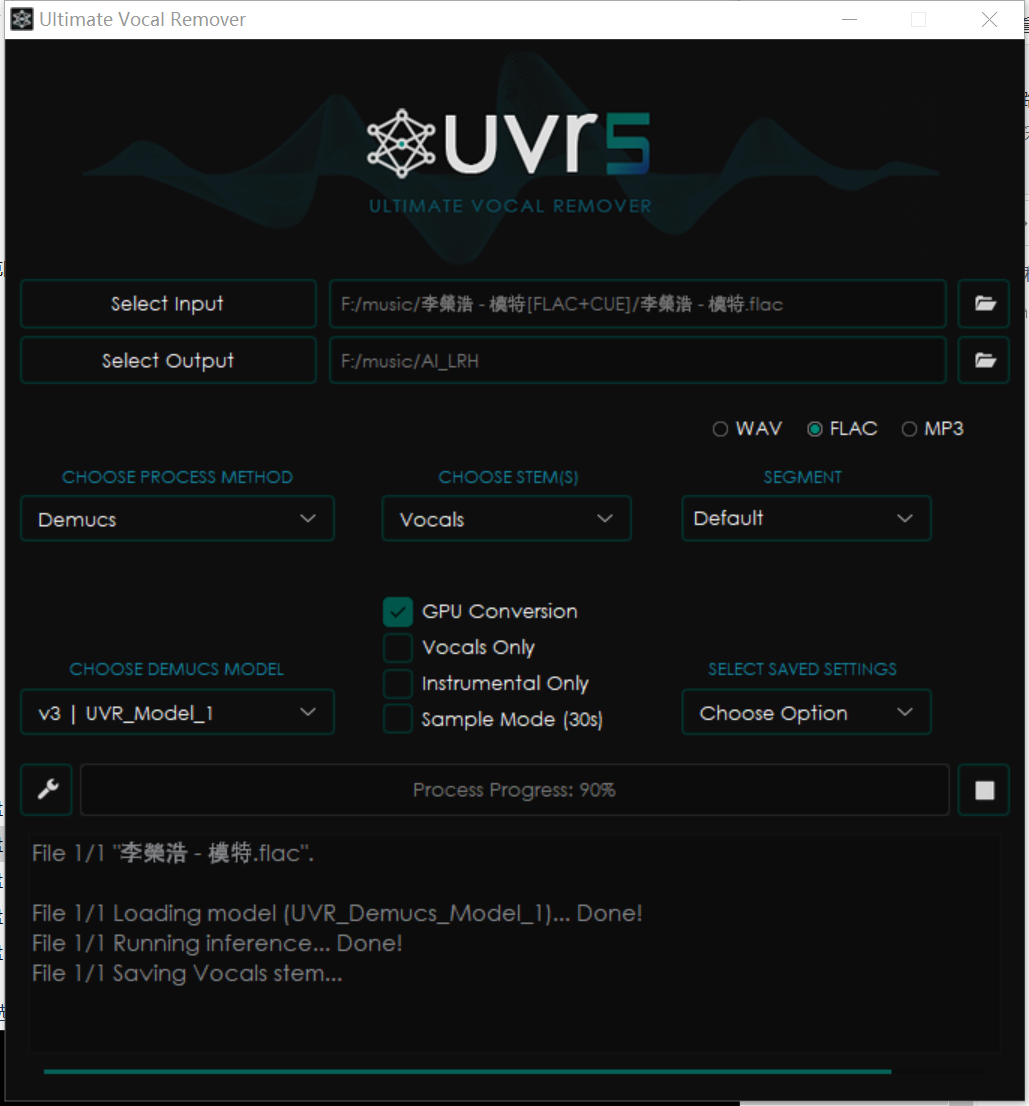
先去掉伴奏,设置如下

再去掉合声,设置如下
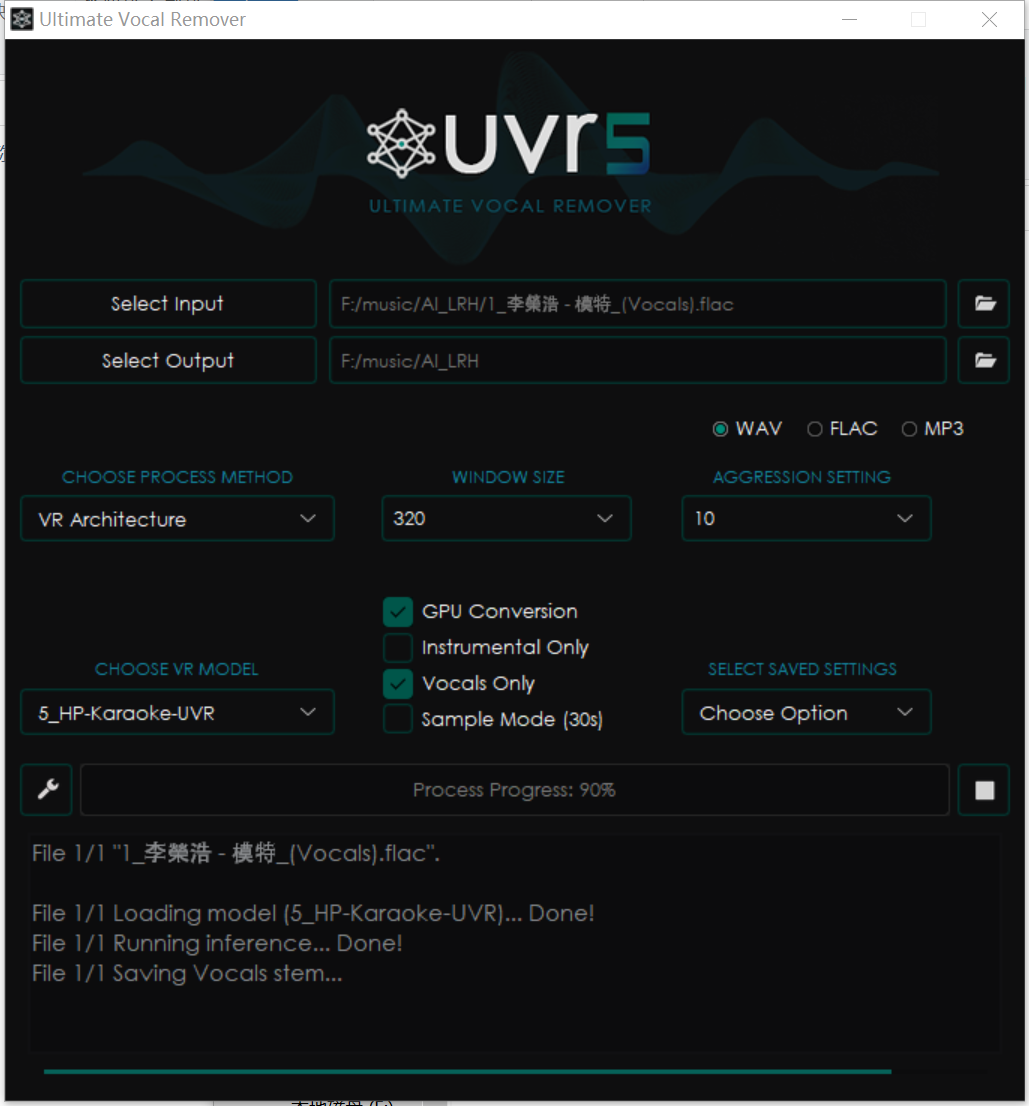
****__(Vocals)_(Vocals).wav就是结果文件了,可以听听,是不是只有人声了
3 文件分隔,一首歌对于显存来说太大了,我们要把人声分隔成更小的文件用到工具Audio Slicer
把文件复制到so-vits-svc-4.0\dataset_raw\{人物名}\下
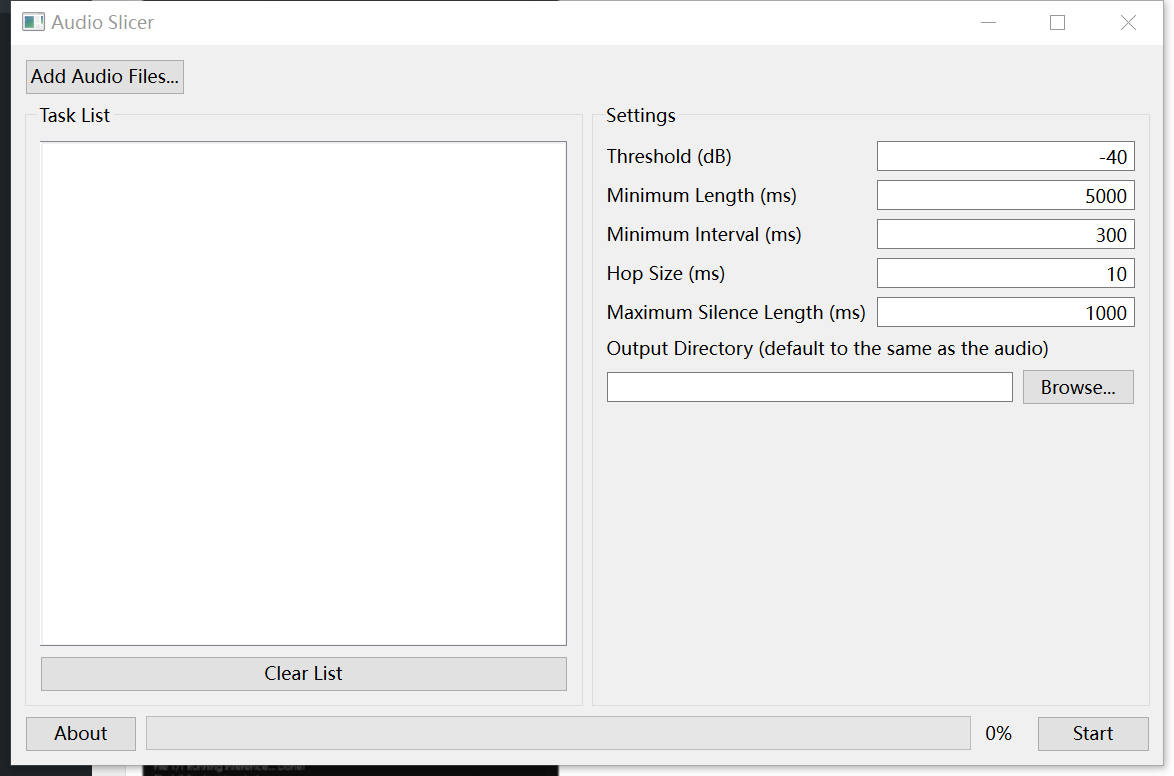
选好路径后,默认参数就可以。
———以上是准备工作——–
4 动行 1、数据预处理
接下来可以直接运行整合包里的脚本 1、数据预处理.bat。
它会在so-vits-svc-4.0\dataset\44k\{人物名}下生成.pt .npy 等文件,等它自动处理完成就可以了
5 运行 2、训练.bat 即可开启训练。
如果你的显卡够好,可以增加 batch_size 提高训练速度,对应的配置文件在 configs/config.json 文件里。
这个训练时间很长,大概需要十几个小时的时间。
(这一步时间很长,可以随机ctrl+c停下来,继续后边的步骤,效果不满意再继续这一步)
6 推理预测
推理预测同理,新运行 3、训练聚类模型.bat 生成数据 pt 文件。几分钟即可跑完。
然后修改 app.py 里的这一行:
model = Svc(“logs/44k/G_35000.pth”, “configs/config.json”, cluster_model_path=”logs/44k/kmeans_10000.pt”)
训练好的模型存放在了 logs/44k 目录下,这里改为你训练好的模型地址,以及对应的配置文件,最后是第三步生成的 pt 文件路径。
记住这里 app.py 必须改好,否则第四步会报错。
7 运行 4、推理预测.bat 文件。
程序会直接开启一个 webui,直接复制到浏览器地址栏中打开即可。
就是一个简单的 Web 页面,里面的参数,可以直接使用默认的,放入一个音频,即可转换音色了。
确认流程都跑通后,可以试着调整一些参数,个人影响太大,主要还是看训练数据,也就是用软件分离的干声质量。
8 处理完的声音是人物的人声没有音乐。要用PR等工具把之前UVR5分离出来的伴奏与人声合成在一起
大功告成!!!
UP主分享的整合包。
https://pan.baidu.com/s/1Jm-p_DZ2IVcNkkOYVULerg?pwd=qi2p